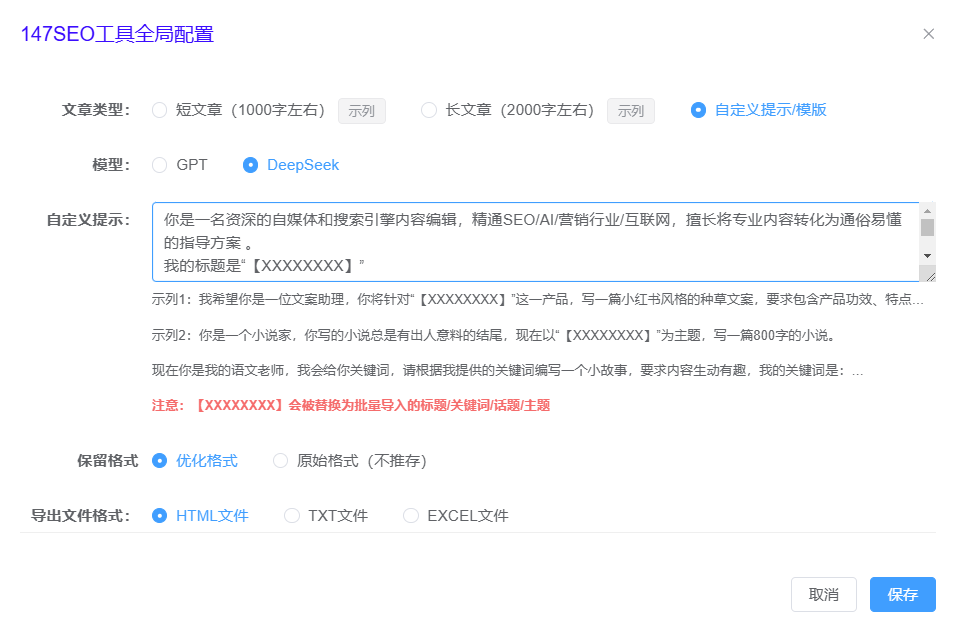
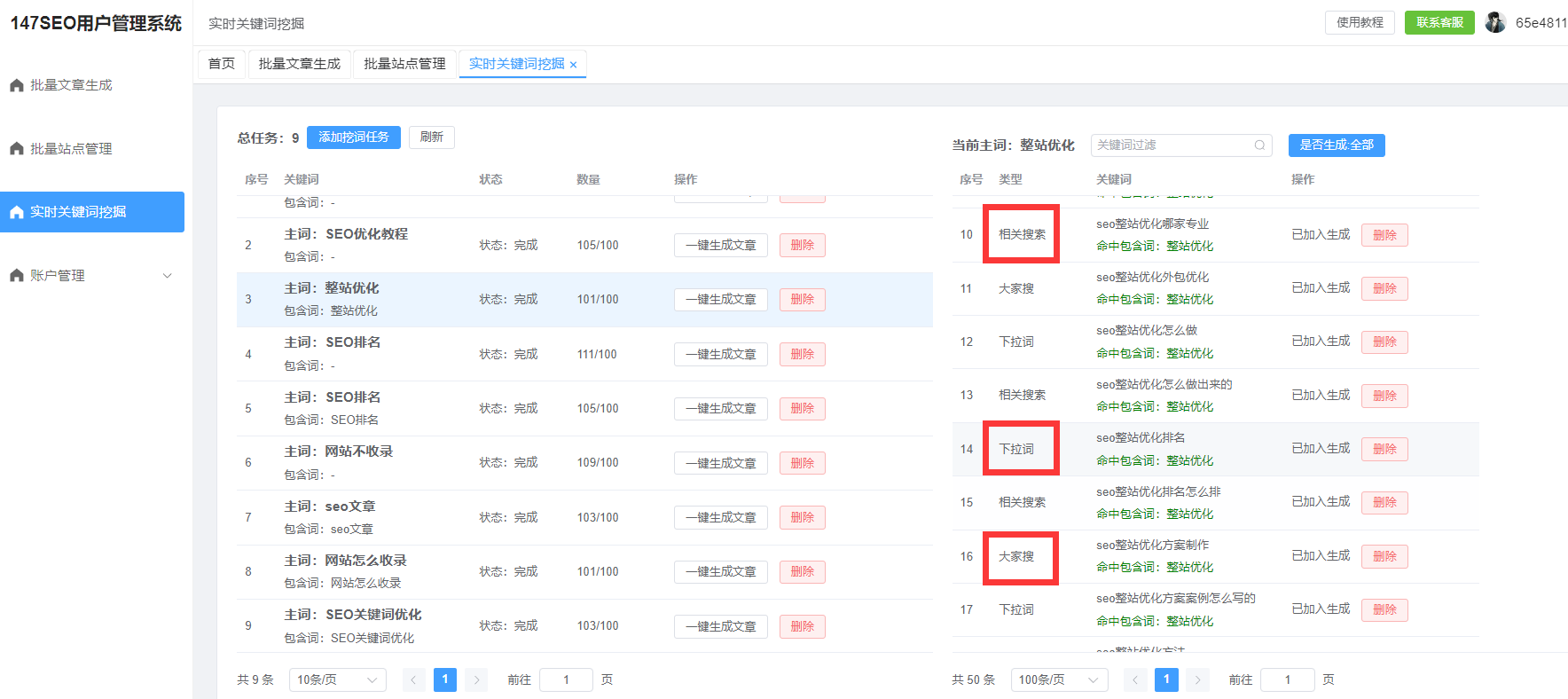
起底揭秘GPT-4:训练参数1.8万亿不开源只是因为好复制
在人工智能的迅猛发展中,GPT-4作为当前最为领先的语言模型,凭借其庞大的训练参数和强大的学习能力,成为了各行各业创新的核心工具。随着它的推出,关于GPT-4的一些细节仍然是科技界热议的话题,尤其是其训练参数的规模、功能的强大以及为何没有选择开源等问题。今天,我们将对GPT-4进行一次深度解析,揭开这个人工智能巨人背后的神秘面纱。

训练参数1.8万亿:人工智能的极限突破
GPT-4的一个最大亮点,便是其惊人的训练参数。作为OpenAI推出的第四代自然语言处理模型,GPT-4的参数量高达1.8万亿个,这一规模无疑让它在目前的人工智能领域中占据了无法撼动的地位。训练参数的增加意味着模型能够处理和理解更多维度的数据,提供更加精确的预测和更高效的对话能力。
1.8万亿个参数的训练量远远超越了以往的模型,使得GPT-4不仅仅是在自然语言理解上实现了突破,同时在多模态学习、跨领域推理以及生成内容的质量上都有了显著的提升。这也使得GPT-4不仅能够更好地理解复杂的语境,还能进行更精确的文本生成,几乎能够“模仿”人类的思维方式,做出与人类相似的反应。

语言理解与生成的革命性进步
与前代的GPT模型相比,GPT-4在语言理解与生成方面的能力有了质的飞跃。通过其庞大的训练数据和先进的深度学习技术,GPT-4能够理解更加复杂和多元的语言表达,它可以精准地理解上下文的语境,做出更加符合人类认知模式的回答。不论是撰写文章、生成创意内容,还是进行技术问题的解答,GPT-4都展现出惊人的创造力和精准性。
特别是在语义的推理能力上,GPT-4能够对一些模糊、复杂的语句进行准确的解读。它不仅能够抓住关键信息,还能够根据语境进行合理的推理和预测,做到真正的“理解”而不仅仅是“匹配”。
除此之外,GPT-4的“多模态”能力也是它的一大亮点。与传统的自然语言处理模型不同,GPT-4不仅能够理解和生成文本信息,还能通过与图像、音频等其他模态的数据进行结合,生成更加多样化的内容。这使得GPT-4可以广泛应用于智能客服、创意写作、医疗诊断、教育辅导等多个领域,展现出强大的跨领域适应能力。
为什么GPT-4不开源?背后的深层原因
尽管GPT-4在技术上取得了巨大的突破,但其一个争议性的决定是:没有选择开源。许多人不禁好奇,作为一款如此强大的人工智能产品,OpenAI为何要限制其开放性?这个问题引发了广泛的讨论。
最直接的原因是GPT-4的训练参数规模庞大,所需要的计算资源和数据量极为庞大。即使是顶尖的科技公司,也很难在短时间内复制出类似的模型。而开源意味着任何人都可以使用和复制这一技术,这可能会导致滥用或误用。因此,OpenAI选择保持对GPT-4的控制,以确保它的使用不被恶意使用,避免其应用在不道德或危险的领域中。
GPT-4的开源意味着将暴露其核心技术,进而可能让竞争对手快速复制和改进,进而导致市场的快速饱和。这对于OpenAI这样的公司而言,无疑会失去巨大的技术优势。而且,开源还可能会使得一些人通过模型的弱点进行“逆向工程”,从而绕过对该技术的监管。因此,OpenAI选择不将GPT-4开源,也是在确保其技术不会轻易地被竞争者超越。
尽管GPT-4不开放源代码,但OpenAI依然通过API的方式向外界提供该模型的能力。这使得开发者和企业可以通过API接入GPT-4的功能,享受其强大的语言生成和理解能力。这样既能够让更多人受益,又能够确保技术的安全性和控制权。
开源与创新之间的博弈
尽管开源一直是推动技术创新的动力之一,但在当前的人工智能领域,开源与创新之间的博弈愈加激烈。开源能够让技术迅速扩展和迭代,但如果没有足够的控制,很容易造成技术被滥用。而对于像GPT-4这样强大的人工智能系统来说,滥用的风险不可忽视。
在未来,是否选择开源,将是人工智能技术发展的一个关键问题。OpenAI的选择或许为我们提供了一种新的思路:在保障技术安全的如何平衡开放与控制,推动创新发展的确保技术应用的道德底线。
GPT-4的推出无疑为人工智能领域注入了新的活力,其庞大的训练参数、强大的功能和不开放的决策背后,透露出人工智能行业对于安全、控制与创新之间的深刻思考。随着技术的不断进步,我们有理由相信,GPT-4仅仅是人工智能领域崭新篇章的开始。
-
上一篇:语音交互:改变生活的智能革命
