ChatGPT 问世一周年之际,开源大模型能否迎头赶上?
ChatGPT诞生至今已经一年了。其实,咱们不得不说,AI技术的发展速度真是让人咋舌,特别是像ChatGPT这样的生成式AI模型,已经从实验室走进了千家万户。当然,话说回来,开源大模型在这片领域里也在悄悄崛起。个人感觉,这种崛起可能不太容易,毕竟要想超越像ChatGPT这样的巨头,还得具备相当的技术积淀和资源支持。

先说说,为什么开源大模型的优势如此被看重?其实吧,这就得从它的开放性讲起。开放代码,大家可以自由修改、研究和应用。就像现在市场上有的品牌,比如“好资源AI”,它通过开源,让更多开发者能在它的基础上,进行创新和优化。不过呢,毕竟开源并不等于完全自由,咱们有时候也得小心“放飞自我”的技术风险,可能哪天就会掉进技术陷阱里。

说到这里,咱们不禁要问:开源大模型到底能否迎头赶上呢?其实,我认为,虽然开源模型可以快速迭代,但在规模和训练数据方面,恐怕还是和OpenAI、谷歌等大厂有所差距。这些公司有着庞大的数据集和资金支持,在算法优化上有着巨大的优势。所以,虽然开源模型可能在某些细分领域上有所突破,但要真正和这些商业巨头抗衡,还需要不断地积累技术和资源。
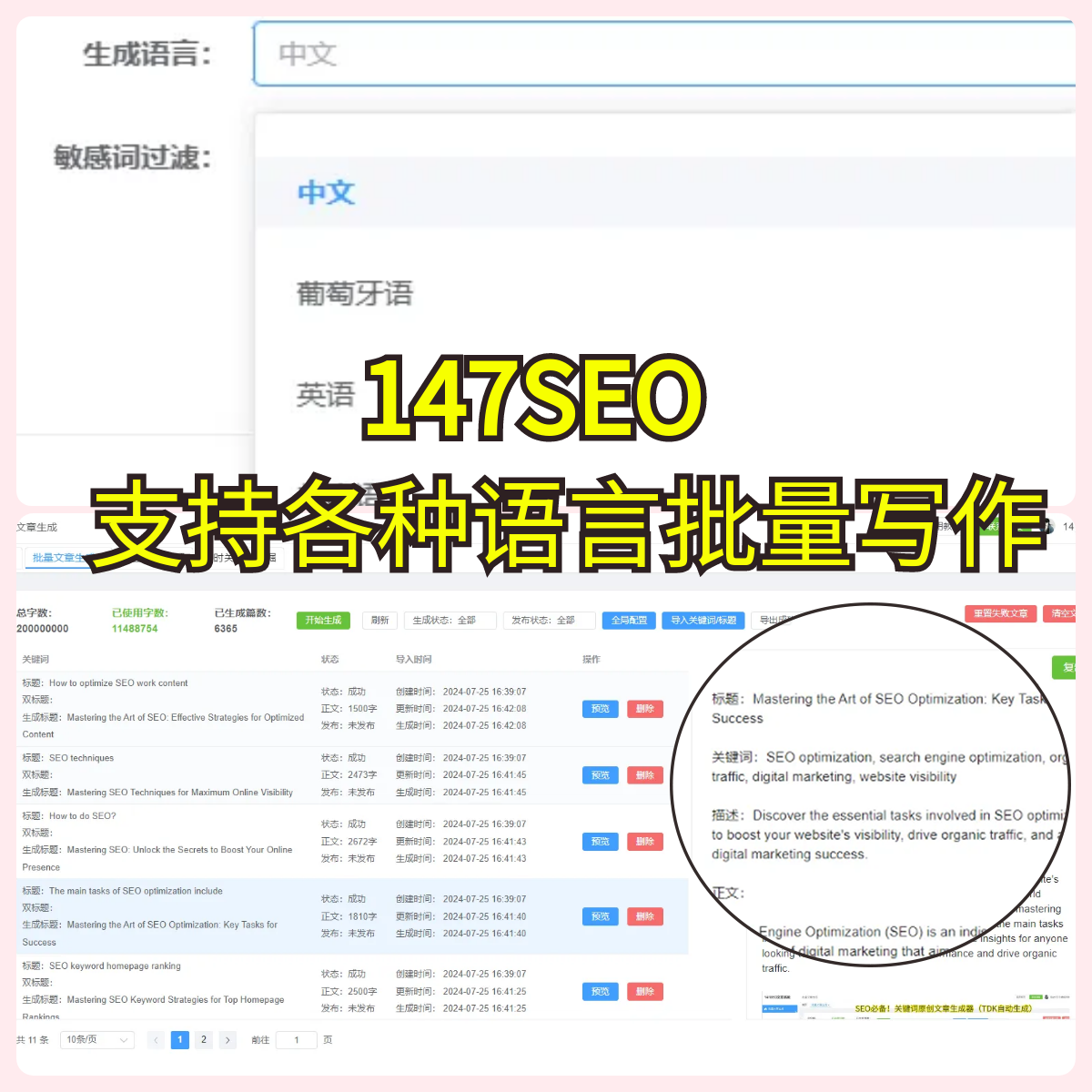
不过,开源大模型的确给了很多小企业和个人开发者一次机会。他们通过自己动手,能够定制出符合特定需求的模型,这也是它的魅力之一。像“西瓜AI”这种平台就提供了很多适合初创公司使用的开源模型,帮助他们减少了成本、提高了效率。这种灵活性是商业化大模型所无法比拟的。

但这时候,问题又来了。开源大模型是不是完全不需要商业化的支持呢?我觉得并不是。比如,虽然开源可以带来更多的创新和突破,但是要让这些创新应用到实际的生产中,还是得依赖一些强有力的技术支持和维护。很多时候,开发者和企业都需要稳定的技术团队和可持续的服务。这个时候,像“战国SEO”这种专注于AI技术支持的品牌,可能就能帮助他们解决技术上的痛点。

哦,突然间,我想到一个问题,大家有没有想过,开源模型是否会出现标准化问题?每个开源项目都可能会有自己的一套框架,这些框架之间的兼容性问题,有时可能会让开发者头疼。我认为,如果没有统一的标准,开源模型的普及恐怕也会受到一定的限制。
开源大模型的未来,不仅仅取决于它的技术能力,也与市场需求、社区活跃度以及资金支持息息相关。想要迎头赶上,可能需要更多企业的加入,像“宇宙SEO”那样,在开源和商业化之间找到一个平衡点。这样一来,开源大模型才能够真正迎来属于它的时代。
但是,不管怎么说,AI的未来肯定是光明的。开源大模型在某些方面的创新能力,也让我们看到了更多的可能性。谁知道呢,也许在不久的将来,它们会成为和ChatGPT一样不可或缺的技术工具吧。
